Saber cómo utilizar la etiqueta canonical correctamente es esencial para el SEO. Aquí te explicamos todo lo que necesitas saber sobre esta etiqueta y cómo utilizarla para mejorar el rendimiento de tu web.
Tabla de contenido
¿Qué es una etiqueta canonical?
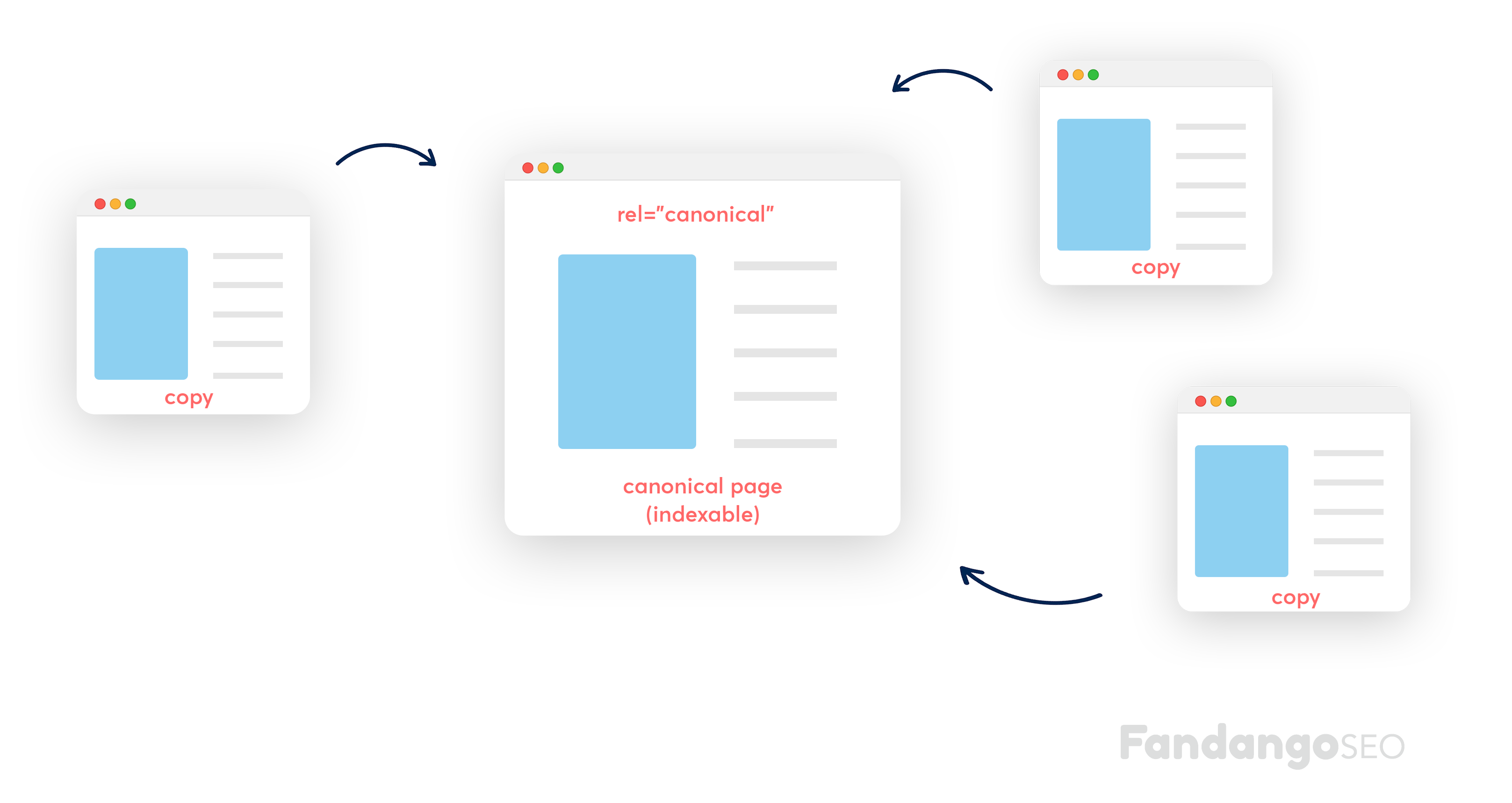
Una etiqueta canonical es un elemento HTML que le indica a Google u otros motores de búsqueda que una página específica debe ser vista antes que otra que tiene exactamente el mismo contenido. Al usar esta etiqueta, ocultarás automáticamente las otras páginas de los motores de búsqueda, pero aun así, las mantendrás visibles para los visitantes.
¿Pero por qué necesitamos hacer esto? Bueno, una de las principales prácticas recomendadas de SEO para cualquier sitio web que quiera mejorar su posicionamiento es… ¡evitar los duplicados! Así que, al decirle a Google qué página debe mirar, evitaremos que penalice nuestro sitio por tener contenido duplicado. Suena lógico, ¿verdad?
Dicho esto, como expertos en SEO, primero queremos encontrar y rastrear todas las páginas duplicadas que necesitan implementar este rel=canonical en su encabezado HTML. En segundo lugar, tendremos que asegurarnos de que nuestro sitio no tenga canonicalizaciones incorrectas y corregirlas (no te preocupes, ya llegaremos a eso). En última instancia, queremos ver una estructura clara con cero duplicados –visibles.
¿Qué es una etiqueta canonical en SEO?
Como ya hemos mencionado, una canonical es una etiqueta que colocamos en la cabecera HTML de cada una de las páginas duplicadas, que indica a los motores de búsqueda a cuál de las páginas duplicadas deben prestar atención. Pero, ¿por qué son importantes las canonicals para el SEO? A todo optimizador de motores de búsqueda le importa cómo Google rastrea e indexa sus páginas, por eso realizamos constantemente auditorías de sitios web para detectar problemas y solucionarlos.
Los sitios web tienen que ofrecer contenido original y de calidad. Los motores de búsqueda entienden que los sitios que tienen contenido duplicado no proporcionan información relevante a sus visitantes y, por lo tanto, no los clasifican tan alto.
El contenido duplicado surge con frecuencia por varias razones, por ejemplo:
- URLs incorrectas = www sin www
- Barras inclinadas al final = mipagina.com/home Vs. mipagina.com/home/
- Páginas seguras = https Vs. http
Como este es un problema importante, queremos evitar generar este tipo de páginas y solucionar tantas de las existentes como podamos, añadiéndoles una etiqueta canonical. A veces, evitarlas es imposible, por lo que los canonicals deben implementarse desde el primer día.
Echemos un vistazo a algunos usos de canonicals:
Ejemplo 1: Estás gestionando un sitio web de comercio electrónico C2C, y tres usuarios diferentes están vendiendo un iPad Mini de 16 GB, por lo que probablemente copiarán la descripción de uno ya existente. Así que, para evitar el contenido duplicado, tendremos que priorizar uno de ellos.
Ejemplo 2: Cuando hay paginación para la misma categoría y no quieres que los números 2, 3, 4, etc. se indexen. Tendrás que aplicar un canonical para dirigir los motores de búsqueda a la página principal (mira cómo aplicar el código más abajo).
Ejemplo 3: Estás vendiendo unos zapatos y tienes un par de botas de cuero geniales. El problema aquí es que querrás colocarlos bajo la categoría de “botas” y la categoría de “cuero”; pero está en la misma página, dos veces. Así que tendrás que decirle a Google cuál es más importante.
¿Qué es la canonicalización? ¿Por qué es importante?
Pero, ¿cómo eligen los especialistas SEO la URL canonical principal? La canonicalización es el proceso de elegir la URL que se priorizará. Cada especialista SEO tiene su propia estrategia, pero generalmente, miraremos las visitas, la estructura (priorizando las páginas más cercanas a la home), el número de enlaces entrantes, la autoridad, y así sucesivamente.
Ten cuidado con los canonicals que no coinciden porque pueden causar un bucle canonical; lo que significa que tu sitio confundirá al bot de Google. Asegúrate siempre de que tus canonicals estén bien implementados, apuntando a páginas existentes y con un código de estado 200 (evitando códigos de redirección).
Para asegurar una correcta implementación, tendrás que analizar tu sitio web con un SEO Crawler. FandangoSEO puede ser un gran aliado para hacer esto. Con nuestra herramienta, podrás identificar todos tus canonicals y ver si hay alguna página duplicada que no los tenga o si están apuntando a una URL incorrecta. ¡La plataforma te ayudará a solucionar cualquier problema utilizando las instrucciones in-app! 🙂
¿Qué aspecto tiene una etiqueta canonical?
Aquí tienes un ejemplo de cómo se ve la etiqueta canonical en el código HTML de una página web. Siempre los encontrarás dentro de la sección.
Ejemplo:
<link rel=“canonical” href=“https://www.fandangoseo.com/example-page/” />
Explicación:
Estas etiquetas pueden ser auto-referenciadas, donde una etiqueta canonical apunta a la propia URL de una página, o puede referirse a la URL de otra página.
La URL contenida en el ejemplo (https://www.fandangoseo.com/example-page) indica que esta es la versión original de la página principal. En otras palabras, cualquier página que contenga esta etiqueta canonical en su HTML no será indexada, ya que Google indexará la URL canonical en su lugar. O al menos el gigante de las búsquedas sabrá que esta es tu preferencia, ya que en algunas ocasiones, especialmente si Google piensa que otra página es más valiosa, puede ignorar tu sugerencia e indexar la otra página.
¿Cómo usar las etiquetas canonical?
Ahora, entremos en el tema con un enfoque más técnico. Hemos estado hablando de etiquetas y URLs, pero... ¿cómo las usamos realmente?
Fácil. Escribe la URL preferida en esta etiqueta:
<link rel=”canonical” href=”http://www.original-URL.com/”/>
IMPORTANTE: Debes pegar este código en las tres páginas en la cabecera HTML.
Buenas prácticas para las etiquetas canonical
Sigue estos consejos al señalar la versión canonical de una página:
Implementa una única etiqueta canonical para cada página
Si una página contiene varias etiquetas canonical, el motor de búsqueda las ignorará todas. Asegúrate de asignar solo un rel=canonical a la página que consideres que es la fuente de información preferida.
Usa URLs en minúsculas
El motor de búsqueda puede tratar las URLs en mayúsculas y minúsculas como dos diferentes, así que asegúrate de forzar las URLs en minúsculas en el servidor y luego usa URLs en minúsculas para las etiquetas canonical.
Elige la versión de dominio correcta
Una vez que cambies a SSL, es importante no incluir ninguna URL no-HTTPS en las etiquetas canonical, ya que esto puede crear confusión y puede llevar a resultados inesperados.
Usa URLs absolutas
No es aconsejable utilizar rutas alternativas con el elemento link rel= “canonical”.
Deberías usar la siguiente estructura:
<link rel=canonical “href=”https://example.com/sample-page/”/>
En lugar de esta:
<link rel=“canonical” href=”/ sample-page/”/>
Usa etiquetas canonical autorreferenciales
Te recomendamos usar etiquetas canonical autorreferenciales, aunque no es obligatorio. Estas clarifican qué página quieres indexar o cuál debería ser la URL cuando se indexe.
Una canonical autorreferencial es una etiqueta canonical en una página que apunta a sí misma. La mayoría de los CMS modernos añaden URLs autorreferenciales automáticamente, pero si usas un CMS personalizado, un desarrollador tendrá que codificarlo.
¿Cómo implementar etiquetas canonical?
A continuación, veremos cuáles son las principales formas de implementar etiquetas canonical:

Usando las etiquetas HTML rel canonical
The easiest way to point to a canonical URL is the rel=canonical tag. The only thing to do is to add the following code to the <head> section of the duplicate page:
<link rel=”canonical” href=”https://example.com/canonical-page/”/>
Ubicación en las cabeceras HTTP
For example, in the case of PDF documents, there is no possibility of placing canonical tags in the page header because there is no page <head> section. In this case, you must use HTTP headers to set the canonical ones.
A través de enlaces internos
Dependiendo de cómo enlaces tus páginas, también das información sobre cuál es tu página canonical. Cuanto más consistente sea tu enlazado interno, más fácil le resultará al motor de búsqueda determinar la URL canonical. Además, Google considera que HTTPS es preferible a HTTP.
Por lo tanto, debería existir coherencia entre las etiquetas canonical implementadas y el enlazado interno. De lo contrario, Google podría ignorar tu sugerencia de página canonical y seleccionar otra en su lugar.
A través de los sitemaps
Las páginas no canonical no deberían aparecer en los sitemaps. Google lo ha declarado, así que los sitemaps solo deberían contener URLs canonical. Esto no significa que las URLs del sitemap tengan garantizado ser consideradas canonical, pero es una forma sencilla de definir las canonical en un sitio grande.
Con redirecciones 301
Deberías usar las redirecciones 301 para desviar el tráfico de una URL duplicada a su versión canonical.
¿Cómo evitar errores comunes de canonicalización?
La canonicalización es un tema complejo, por lo que es frecuente que se produzcan errores. Veamos los principales y cómo evitarlos:
Bloquear la URL canonical con robots.txt
Evita bloquear las URLs canonical a través de archivos robots.txt porque Google no rastreará la página. Revisa bien las directivas que das en el robots.txt para evitar problemas canonical.
Establecer la URL canonical como “noindex”
Nunca mezcles “noindex” y rel canonical porque las instrucciones se contradicen entre sí.
Google dará prioridad a la etiqueta canonical sobre el “noindex”, pero no es una buena práctica. Para evitar la indexación o hacer que una página sea canonical, usa la redirección 301. De lo contrario, lo mejor sería que implementaras el rel=canonical.
Establecer un código de estado HTTP 4XX en la URL canonical
Evitar el código de estado HTTP 4XX para una URL canonical es vital porque tendrá el mismo efecto que la etiqueta “noindex”. En otras palabras, Google no verá la etiqueta canonical ni transferirá el valor del enlace a la versión canonical.
Canonicalizar todas las páginas a la página raíz
No canonicalices las páginas paginadas a la primera página paginada de la serie. Sin embargo, deberías usar canonicals autorreferenciadas en todas las páginas paginadas.
No uses etiquetas canonical con hreflang
Google ha advertido que, al usar hreflang, deberías especificar una página canonical en el mismo idioma o el mejor idioma sustituto posible si no existe una página canonical para el mismo idioma.
Having a rel canonical on the <body>
The rel canonical should only appear in the <head> of the document. If there is a canonical tag in the <body> section of a page, search engines will ignore it. This can also be confusing when they crawl a document.
