Are you experiencing Google indexing problems? This trouble may lead to traffic and conversion rates dropping.
It is necessary to check the indexed and unindexed pages of your site to solve any issue quickly. Here we explain step-by-step how to do it with the Google Search Console – Index Coverage Report.
With the following method, we have managed to fix index coverage issues on hundreds of websites with millions or billions of excluded pages. Use it so that none of your relevant pages lose visibility in search results and boost your SEO traffic!
Table of Contents
Step 1: Check the index coverage report
The Search Console Coverage Report tells you which pages have been crawled and indexed by Google and why the URLs are in that particular state. You can use it to detect any errors found during the process of crawling and indexing.
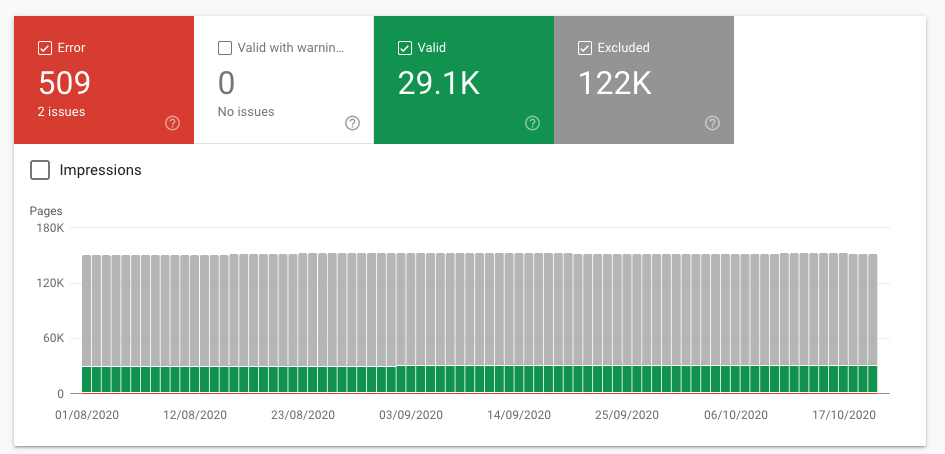
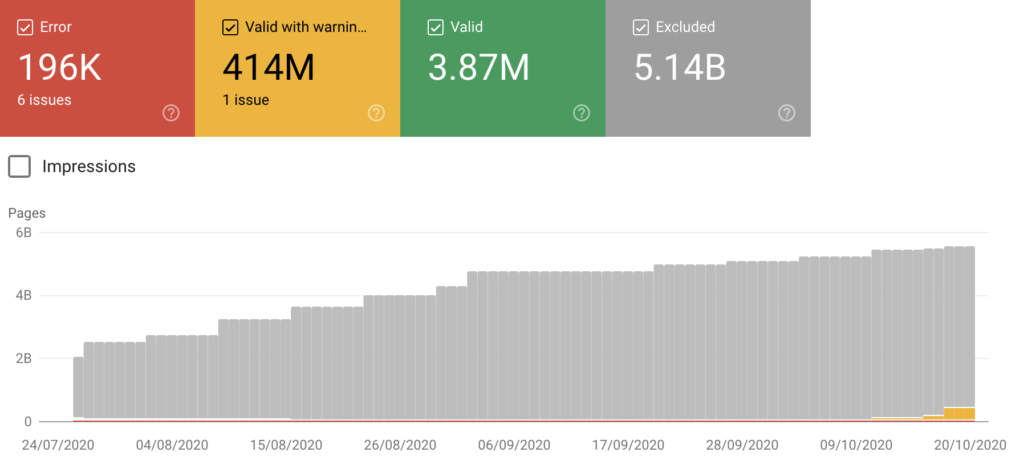
To check the index coverage report, go to the Google Search Console and click on Coverage (just below Index). Once you open it, you’ll see a summary with four different status categorizing your URLs:
Error: These pages cannot be indexed and won’t appear in search results due to some errors.
Valid with warnings: These pages may or may not be shown on Google search results.
Valid: These pages have been indexed and can be shown on search results. You don’t need to do anything.
Excluded: These pages were not indexed and won’t appear in search results. Google believes that you don’t want to index them or consider that the content is not worth indexing.
You need to check all the pages found on the Error section and correct them ASAP because you might be losing the opportunity to drive traffic to your site.
If you have time, look at the pages included in the state Valid with warning as there may be some vital pages that under no circumstances should fail to appear in the search results.
Finally, ensure the excluded pages are the ones you do not want to be indexed.
Before we go into detail about how to solve the coverage issues, it is worth mentioning a few things about the valid URLs.
Valid URLs
We can differentiate between two types of valid URLs:
Submitted and indexed
Indexed, not submitted in sitemap
The URLs in the category of submitted and indexed are those you have included in the XML sitemap, and consequently, Google has indexed. You don’t need to take any action in this case.
On the other hand, the URL listed as “indexed, not submitted in sitemap” are those Google has found and indexed, even though you did not include them in the XML sitemap.
Actions to take:
Make sure you want these pages to be indexed, and if so, add them to the XML sitemap. If not, you will have to assign the meta robots noindex tag.
Step 2: How to solve the problems found in each of the Index Coverage Status
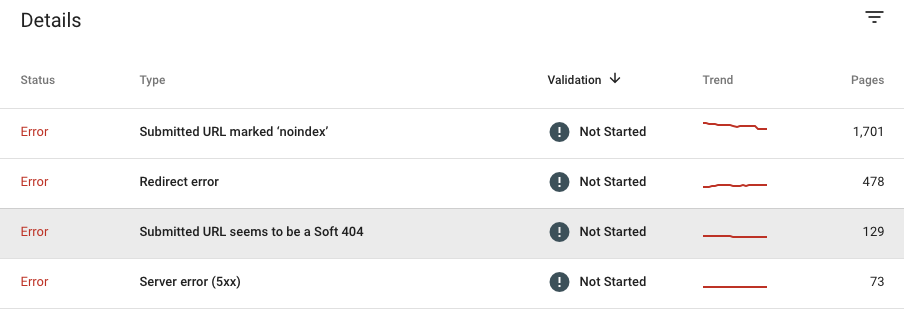
Once you open the Index Coverage Report, select the desired status (Errors, Valid with warnings, or Excluded) and see the details provided at the bottom of the page. You’ll find a list of error types by its severityand the number of pages affected, so we recommend starting to investigate the issues from the top of the table.
Let’s see each of the errors in different statuses and how you can fix them.
Error status
Server errors (5xx):
These are URLs returning a 5xx server error status code to Google.
Actions to take:
Check what kind of 500 status code is returning. Here you have a complete list with the definition for each server error status code.
Reload the URL to see if the error persists. 5xx errors are temporary and don’t require any action.
Verify that your server is not overloaded or misconfigured. In that case, ask your developers for help, or contact your hosting provider.
Perform a Log File Analysis to check the error logs for your server. This practice provides you extra information about the issue.
Review the changes you’ve made recently to your website to see if any of them may be the root cause. ex) plugins, new backend code, etc.
Redirect errors:
GoogleBot has encountered an error during the redirection process that does not allow to crawl the page. Any of the following reasons often causes redirect errors.
A redirect chain that was too long
A redirect loop
A redirect URL that exceeded the max URL length
There was wrong or empty URL in the redirect chain
Actions to take:
Eliminate the redirect chains and loops. Have each URL perform only one redirection. In other words, a redirect from the first URL to the last one.
Submitted URL blocked by Robots.txt:
These are URLs that you have submitted to Google uploading an XML Sitemap to Google Search Console but have been blocked by the Robots.txt file.
Actions to take:
Check whether you want search engines to index the page in question or not.
If you don’t want it to be indexed, upload an XML sitemap removing the URL.
On the contrary, if you want it to be indexed, change the guidelines in the Robots.txt. Here is a guide on how to edit robots.txt.
Submitted URL marked “noindex”:
These pages have been submitted to Google through an XML sitemap, but they have a ‘noindex’ directive either in meta robots tag or HTTP headers.
Actions to take:
If you want the URL to be indexed, you should remove the noindex directive
If there are URLs that you don’t want Google to index, eliminate them from the XML Sitemap
The submitted URL seems to be a Soft 404:
The URL that you have submitted through an XML Sitemap for indexing purposes is returning a soft 404. This error happens when the server returns a 200 status code to a request, but Google believes it should display a 404. In other words, the page looks like a 404 error to Google. In some cases, it might be because the page has no content, seems wrong, or of low quality to Google.
Actions to take:
Investigate whether these URLs should return a (real) 404 Status code. In that case, remove them from the XML sitemap.
If you find that they should not return an error, make sure you provide appropriate content on these pages. Avoid thin or duplicate content. Verify that if there are redirections, they are correct.
Submitted URL returns unauthorized request (401):
The URL submitted to Google through an XML Sitemap returns a 401 error. This status code tells you that you’re not authorized to access the URL. You may need a username and password, or perhaps, there are access restrictions based on the IP address.
Actions to take:
Check whether the URLs should return a 401. In that case, eliminate them from the XML sitemap.
If you don’t want them to display a 401 code, remove the HTTP Authentication if there’s any.
Submitted URL not found (404):
You have submitted the URL for indexing purposes to Google Search Console, but Google cannot crawl it due to an issue different from those mentioned above.
Actions to take:
See if you want the page to be indexed or not. If the answer is yes, fix it, so it returns a 200 status code. You can also assign a 301 redirect to the URL, so it displays an appropriate page. Remember that if you opt for a redirect, you need to add the assigned URL to the XML sitemap and remove the one giving a 404.
If you don’t want the page to be indexed, remove it from the XML sitemap.
Submitted URL has crawl issue:
You have submitted the URL for indexing purposes to GSC but it cannot be crawled by Google due to an issue different from those mentioned above.
Actions to take:
Use the URL Inspection Tool to get more information on what is causing the issue.
Sometimes these errors are temporary, so they do not require any action.
Valid with Warning Status
These pages are indexed, although they are blocked by robots.txt. Google always tries to follow the directives given in the robots.txt file. However, sometimes it behaves differently. This can happen, for example, when someone links to the given URL.
You find the URLs in this category because Google doubts whether you want to block these pages on search results.
Actions to take:
Google does not recommend using the robots.txt file to avoid page indexation. Instead, if you don’t want to see these pages indexed, use the noindex in the meta robots or an HTTP response header.
Another good practice to prevent Google from accessing the page is by implementing an HTTP Authentication.
If you don’t want to block the page, make the necessary corrections in the robots.txt file.
You can identify which rule is blocking a page using the robots.txt tester.
Natzir Turrado,
FandangoSEO Advisor
Technical SEO Freelance @ Natzir Turrado
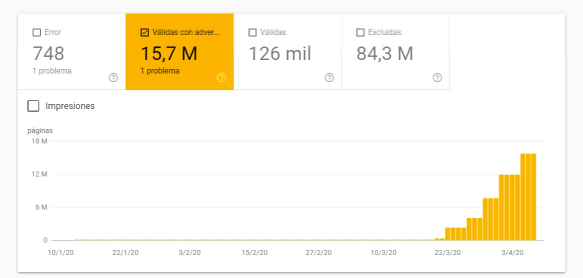
On a large migration to SalesForce, we asked the developers to make the filters we didn’t want to index inaccessible (obfuscated). When the Salesforce website went live, everything was a success. But when a new version was released months later, the obfuscation was accidentally broken. This set off all the alarms since, in only seven days, there were ~17.5 million Googlebot-Mobile requests and ~12.5 million Googlebot/2.1, as well as a 2% hit rate cache. Below you can see in Search Console how the pages indexed but blocked by robots increased.
This is why I recommend continuously monitoring the logs and reviewing the GSC Coverage Report (although you’ll detect any issue sooner checking the logs). And remember that the robots.txt does not prevent pages from being indexed. If you want Google not to crawl a URL, it is best to make the URL inaccessible!
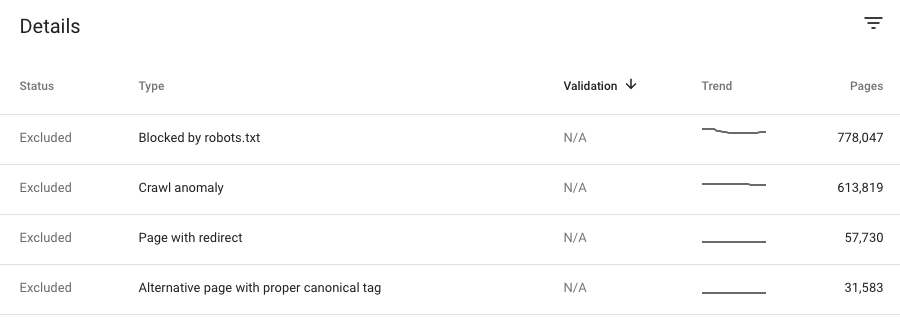
Excluded Status
These pages are not indexed on search results, and Google believes it’s the right thing. For example, this could be because they are duplicated pages of indexed pages or because you give guidelines on your website to search engines to not index them.
The Coverage report shows you 15 situations in which your page can be excluded.
Excluded by ‘noindex’ tag:
You are telling search engines not to index the page by giving a “noindex” directive.
Actions to take:
Verify if you actually don’t want to index the page. If you want the page to be indexed, remove the “noindex” tag.
You can confirm this directive’s presence by opening the page and searching for “noindex” on the response body and response header.
Blocked by page removal tool:
You have submitted a URL removal request for these pages on GSC.
Actions to take:
Google only attends this request for 90 days, so if you don’t want to index the page, use “noindex” directives, implement an HTTP Authentication, or remove the page.
Blocked by robots.txt:
You are blocking the access to Googlebot to these pages with the robots.txt file. However, it could still be indexed if Google could find information about this page without loading it. Perhaps Google indexed the page before you added the disallow in robots.txt
Actions to take:
If you don’t want the page to be indexed, use a “noindex” directive and remove the robots.txt block.
Blocked due to unauthorized request (401):
You are blocking the access to Google using a request authorization (401 response).
Actions to take:
If you want to allow GoogleBot to visit the page, remove the authorization requirements.
Crawl anomaly:
The page was not indexed due to a 4xx or 5xx error response code.
Actions to take:
Use the URL Inspection tool to get more information about the issues.
Crawled – Currently not indexed
The page with a “crawled – currently not indexed” status was crawled by GoogleBot but not indexed. It may or may not be indexed in the future. There’s no need to submit this URL for crawling.
Actions to take:
For a “crawled – currently not indexed” page, if you want it to be indexed in the search results, make sure you provide valuable information on it.
Discovered – Currently not indexed:
Google found this page, but it has yet not managed to crawl it. This situation usually happens because when GoogleBot tried to crawl the page, the site was overloaded. The crawl has been scheduled for another time.
No action is required.
Alternate page with the proper canonical tag:
This page points to a canonical page, so Google understands that you don’t want to index it.
Actions to take:
If you want to index this page, you’ll need to change the rel=canonical attributes to give Google the wished guidelines.
Duplicate without user-selected canonical:
The page with a “duplicate without user-selected canonical” status has duplicates, but none of them is marked as canonical. Google considers that this one is not the canonical one.
Actions to take:
Use canonical tags to make it clear to Google which pages are the canonical ones (must be indexed) and which ones are the duplicates. You can use the URL Inspection Tool to see which pages have been selected as canonicals by Google. This way, you’ll be able to avoid the duplicate without user-selected canonical issue.
Duplicate, Google chose different canonical than user:
You have marked this page as canonical, but Google, instead, has indexed another page that thinks functions better as canonical.
Actions to take:
You can follow Google’s choice. In that case, mark the indexed page as canonical and this one as a duplicate of the canonical URL.
If not, find out why Google prefers another page over the one you’ve chosen, and make the necessary changes. Use the URL Inspection Tool to discover the “canonical page” selected by Google.
One of the most curious “fails” we’ve experienced with the Index Coverage Report was finding that Google was not processing our canonicals correctly (and we had been doing it wrong for years!). Google was indicating on the Search Console that the specified canonical was invalid when the page was perfectly formatted. In the end, it turned out to be a bug from Google itself, confirmed by Gary Ilyes.
Not found (404):
The page is returning a 404 error status code when Google makes a request. GoogleBot did not find the page through a sitemap, but probably through another website linking to the URL. It is also possible that this URL existed in the past and has been removed.
Actions to take:
If the 404 response is intentional, you can leave it as it is. It won’t harm your SEO performance. However, if the page has moved, implement a 301 redirect.
Page removed because of legal complaint:
This page was eliminated from the index due to a legal complaint.
Actions to take:
Investigate what legal rules you may have infringed and take the necessary actions to correct it.
Page with the redirect:
This URL is a redirect and therefore was not indexed.
Actions to take:
If the URL was not supposed to redirect, remove the redirect implementation.
Soft 404:
The page returns what Google believes is a soft 404 response. The page is not indexed because, although it gives a 200 status code, Googles thinks it should be returning a 404.
Actions to take:
Review if you should assign a 404 to the page, as Google suggests.
Add valuable content to the page to let Google know that it is not a Soft 404.
Duplicate, submitted URL not selected as canonical:
You have submitted the URL to GSC for indexing purposes. Still, it has not been indexed because the page has duplicates without canonical tags, and Google considers that there is a better candidate for canonical.
Actions to take:
Decide if you want to follow Google’s choice for the canonical page. In that case, assign the rel=canonical attributes to point to the page selected by Google.
You can use the URL Inspection Tool to see which page has been chosen by Google as the canonical.
If you want this URL as the canonical, analyze why Google prefers the other page. Offer more high-value content on the page of your choice.
Step 3. Index Coverage Report Most Common Issues
Now you know the different types of errors that you can find in the Index Coverage report and what actions to take when you encounter each of them. The following is a short overview of the issues that most frequently arise.
More Excluded than Valid Pages
Sometimes you can have more excluded pages than valid ones. This circumstance usually is given on large sites that have experienced a significant URL change. It is probably an old site with a long history, or the web code has been modified.
If you have a significant difference between the number of pages of the two statuses (Excluded and Valid), you have a severe problem. Start reviewing the excluded pages, as we explain above.
The biggest issue I have ever seen in the Coverage Report is one of the websites I manage, which ended up having 5 billion excluded pages. Yes, you read it correctly, 5 billion pages. The faceted navigation went completely crazy, and for every pageview, we were creating 20 new URLs for Googlebot to crawl.
That ended up being the most expensive mistake in terms of crawling, ever. We had to completely disallow via the robots.txt the faceted navigation URLs as Googlebot was taking down our server with more than 25 million hits a day.
Error spikes
When the number of errors increases exponentially, you need to check the error and fix it ASAP. Google has detected some problem that severely damages the performance of your website. If you don’t correct the issue today, you’ll have significant problems tomorrow.
Server errors
Make sure these errors are not 503 (Service Unavailable). This status code means that the server cannot handle the request due to a temporary overload or maintenance. At first, the error should disappear by itself, but if it keeps occurring, you must look at the problem and solve it.
If you have other types of 5xx errors, we recommend checking our guide to see the actions you need to take in each case.
404 errors
It seems like Google has detected some area of your website that is generating 404 – not found pages. If the volume grows considerably, review our guide to find and fix broken links.
Missing pages or sites
If you cannot see a page or a site in the report, it can be for several reasons.
Google has not discovered it yet. When a page or site is new, it may take some time before Google finds it. Submit a sitemap or page crawl request to accelerate the indexing process. Also, make sure that the page is not an orphan and linked from the website.
Google cannot access your page due to a login request. Remove the authorization requirements to allow GoogleBot to crawl the page.
The page has a noindex tag or was dropped from the index for some reason. Remove the noindex tag and make sure that you are providing valuable content on the page.
“Submitted but/Submitted and” errors and exclusions
This problem occurs when there is incongruence. If you send a page through a sitemap, you have to make sure that it’s valid for indexing, and that’s linked to the site.
Your site should consist mostly of valuable pages that are worth interlinking.
Summary
Here’s a three-step summary of the article “How to find and fix index coverage errors.”
The first thing you want to do when using the index coverage report is to fix the pages that appear in the Error status. This must be 0 to avoid Google penalties.
Secondly, check the excluded pages and see if these are pages that you do not want to index. If this is not the case, follow our guidelines to solve the issues.
If you have time, we strongly recommend checking the valid pages with a warning. Make sure that the guidelines you give in the robots.txt are correct and that there are no inconsistencies.
We hope you find it helpful! Let us know if you have any questions regarding the index coverage report. We would also love to hear any tips from you in the comments below.