Knowing how to use the canonical tag correctly is essential for SEO. Here we explain everything you need to know about this tag and how to use it to improve your web performance.
Table of Contents
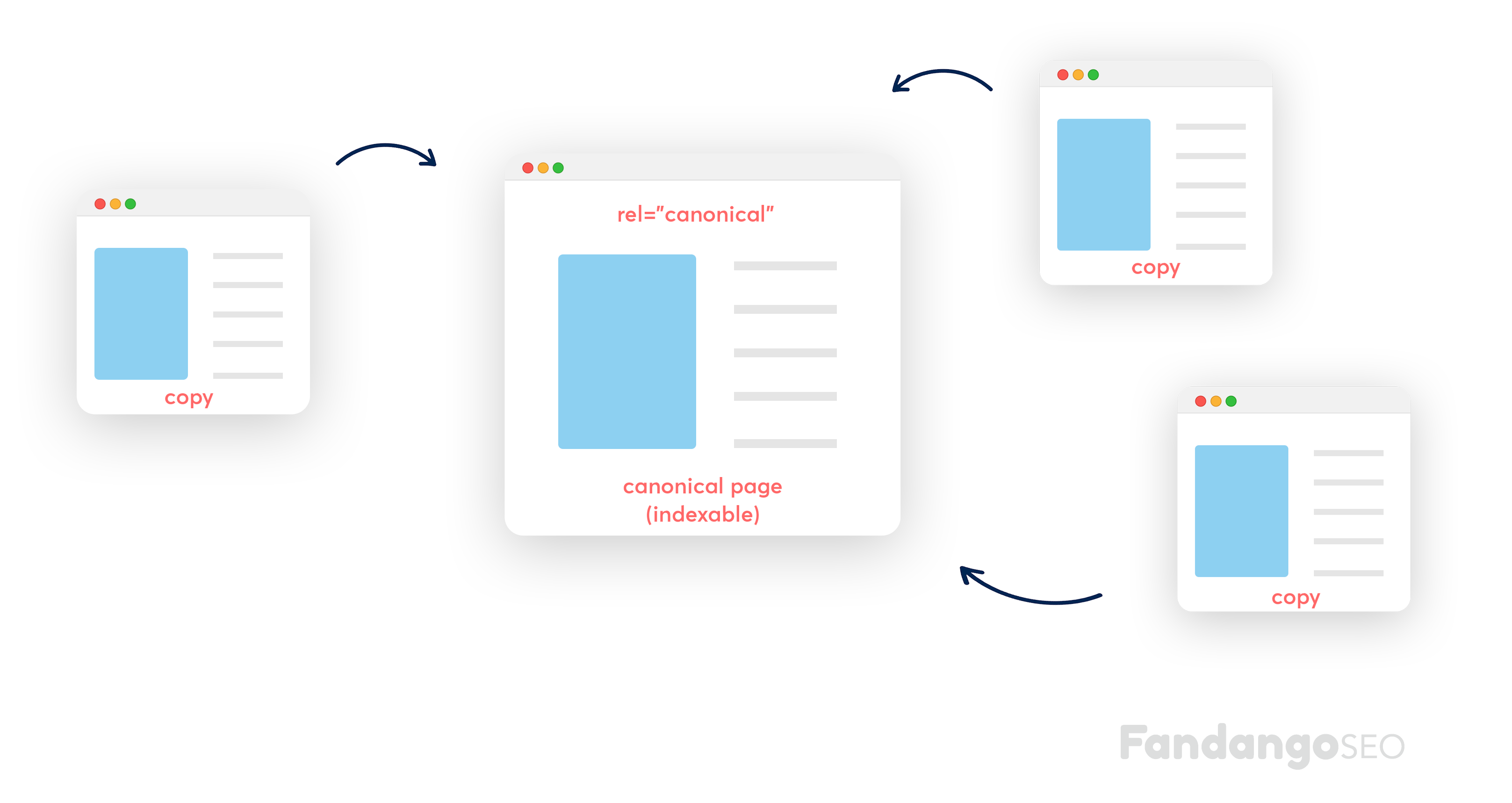
What is a canonical tag
A canonical tag is an HTML element that indicates to Google or other search engines that a specific page should be seen before another one that has the exact same content. By using this tag, you will automatically hide the other pages from search engines, but still, keep them visible to visitors.
But why do we need to do this? Well, one of the top SEO best practices for any website that wants to raise its rankings is… to avoid duplicates! So by telling Google which page to look at, we will prevent them from penalizing our site for having duplicate content. Sounds logical, right?
This being said, as SEO experts, we first want to find and track all the duplicated pages that need to implement this rel=canonical on their HTML header. Secondly, we will need to make sure that our site doesn’t have wrong canonicalizations, and fix them (don’t worry, we’ll get there). Ultimately, we want to see a clear structure with zero –visible- duplicates.
What is a canonical tag in SEO?
As we already mentioned, a canonical is a tag that we place on the HTML header of each of the duplicated pages, which indicates to search engines which one of the duplicated pages they should pay attention to. But why are canonicals important for SEO? Every search engine optimizer cares about how Google crawls and indexes its pages, which is why we constantly conduct website audits, to detect issues and fix them.
Websites have to offer quality and original content. Search engines understand that sites that have duplicate content do not provide relevant information to their visitors and therefore do not rank them as highly.
Duplicate content arises regularly for multiple reasons, for example:
- Wrong URLs = www non-www
- Trail slashes = mypage.com/home Vs. mypage.com/home/
- Secure pages = https Vs. http
As this is a major problem, we want to avoid generating these types of pages and fix as many of the existing ones as we can, by adding a canonical tag to them. Sometimes, avoiding them is impossible, so the canonicals must be implemented from day one.
Let’s have a look at some canonical uses:
Example 1: You’re running a C2C e-commerce website, and three different users are selling an iPad Mini 16GB, so they will most probably copy the description of an existing one. So to avoid duplicate content we will have to prioritize one of them.
Example 2: When there’s pagination for the same category and you don’t want numbers 2, 3, 4, etc. to be indexed. You will have to apply a canonical to direct search engines to the main page (see how to apply the code below.)
Example 3: You’re selling some shoes and you have a pair of cool leather boots. The issue here is that you will want to place them under the “boots” category and the “leather” category; but it is on the same page, twice. So you will have to tell Google which one is more important.
What is canonicalization? Why is it important?
But how do SEO specialists choose the main canonical URL? Canonicalization is the process of picking the URL that will be prioritized. Every SEO Specialist has their own strategy, but generally, we will look at the visits, the structure (prioritizing the pages closer to the home), the number of incoming links, the authority, and so on.
Beware of non-matching canonicals because they can cause a canonical loop; meaning your site will confuse the Google bot. Always ensure that your canonicals are well implemented, pointing to existing pages, and with a 200 status code (avoiding redirect codes).
To ensure correct implementation, you’ll have to analyze your website with an SEO Crawler. FandangoSEO can be a great ally for doing this. With our tool, you’ll be able to identify all your canonicals and see if there are any duplicate pages that don’t have them or if they are pointing to a wrong URL. The platform will help you fix any issues using the in-app instructions! 🙂
What does a canonical tag look like
Here’s an example of what the canonical tag looks like in the HTML code of a web page. You’ll always find them within thesection.
Example:
<link rel=“canonical” href=“https://www.fandangoseo.com/example-page/” />
Explanation:
These labels can be self-referenced, where a canonical tag points to a page’s own URL or can refer to another page’s URL.
The URL contained in the example (https://www.fandangoseo.com/example-page ) indicates that this is the original version of the parent page. In other words, any page containing this canonical tag in its HTML will not be indexed, as Google will index the canonical URL instead. Or at least the search giant will know that this is your preference as on some occasions, especially if Google thinks another page is more valuable, it may pass on your suggestion and index the other page.
How to use canonical tags
Now, let’s get into the topic with a more technical approach. We’ve been talking about tags and URLs, but… how do we actually use them?
Easy. Type the preferred URL in this tag:
<link rel=”canonical” href=”http://www.original-URL.com/”/>
IMPORTANT: You must paste this code on all three pages in the HTML header.
Best practices for canonical tags
Follow these tips when pointing out the canonical version of a page:
Implement a single canonical tag for each page
If a page contains several canonical tags, the search engine will ignore them all. Make sure to assign only one rel=canonical to the page you consider to be the preferred source of information.
Use lowercase URLs
The search engine can treat uppercase and lowercase URLs as two different ones, so be sure to force lowercase URLs on the server and then use lowercase URLs for canonical tags.
Choose the right domain version
Once you switch to SSL, it is important not to include any non-HTTPS URLs in the canonical tags, as this can create confusion and may lead to unexpected results.
Uses absolute URLs
It is not advisable to use alternative routes with the link element rel= “canonical”.
You should use the following structure:
<link rel=canonical “href=”https://example.com/sample-page/”/>
Instead of this one:
<link rel=“canonical” href=”/ sample-page/”/>
Use self-referential canonical tags
We recommend using self-referential canonical tags, although it’s not mandatory. They clarify which page you want to index or what the URL should be when it is indexed.
A self-referential canonical is a canonical tag on a page that points to itself. Most modern CMSs add self-referential URLs automatically, but it needs to be coded by a developer if you use a custom CMS.
How to implement canonical tags
Next, we will see what the main ways to implement canonical tags are:

Using the HTML rel canonical tags
The easiest way to point to a canonical URL is the rel=canonical tag. The only thing to do is to add the following code to the <head> section of the duplicate page:
<link rel=”canonical” href=”https://example.com/canonical-page/”/>
Placement in the HTTP headers
For example, in the case of PDF documents, there is no possibility of placing canonical tags in the page header because there is no page <head> section. In this case, you must use HTTP headers to set the canonical ones.
Through Internal Links
Depending on how you link your pages, you also give information about which is your canonical page. The more consistent your internal linking, the easier it will be for the search engine to determine the canonical URL. Also, Google considers HTTPS to be preferable to HTTP.
Therefore, coherence between the implemented canonical tags and internal linking should exist. Otherwise, Google may ignore your suggestion of a canonical page and may select another one instead.
Through the sitemaps
Non-canonical pages should not appear on sitemaps. Google has stated this, so sitemaps should only contain canonical URLs. This does not mean that the sitemap URLs are guaranteed to be considered canonical, but it is an easy way to define the canonical ones on a large site.
With redirects 301
You should use the 301 redirects to divert traffic from a duplicate URL to its canonical version.
How to Avoid Common Canonicalization Mistakes
Canonicalization is a complex issue so that errors may occur frequently. Let’s see the main ones and how to avoid them:
Blocking the canonical URL with robots.txt
Avoid blocking the canonical URLs via robots.txt files because Google will not crawl the page. Double-check the directives you give on the robots.txt to avoid canonical issues.
Setting the canonical URL as “noindex”
Never mix “noindex” and rel canonical because instructions contradict each other.
Google will prioritize the canonical tag over the “noindex,” but this is not good practice. To avoid indexing or make a page canonical, use the 301 redirect. Otherwise, it would be best if you implement the rel=canonical.
Setting an HTTP 4XX status code in the canonical URL
Avoiding the HTTP 4XX status code for a canonical URL is vital because it will have the same effect as the “noindex” tag. In other words, Google will not see the canonical tag or transfer the link value to the canonical version.
Canonicalizing all pages to the root page
Do not canonicalize paginated pages to the first paginated page of the series. However, you should use self-referenced canonicals on all paginated pages.
Do not use canonical tags with hreflang
Google has warned that when using hreflang, you should specify a canonical page in the same language or the best possible substitute language if no canonical page exists for the same language.
Having a rel canonical on the <body>
The rel canonical should only appear in the <head> of the document. If there is a canonical tag in the <body> section of a page, search engines will ignore it. This can also be confusing when they crawl a document.
